Do you use Apache Solr? We do, it is fantastic! Do you realise that it is one of the most widely deployed and trusted search platforms on the planet? The latest version offers many sophisticated features – like querying via SQL – are not even available in commercial enterprise search products. And, of course, Solr is open source.
For all of these benefits, implementing a search solution using Solr requires many, if not all of the following tasks:
- Implementing an indexing architecture to retrieve documents from all necessary data sources – potentially including Microsoft SharePoint, EDRMS systems, Google Drive, Box, Salesforce, Drupal, Amazon S3, ServiceNow, ZenDesk.
- Performing any necessary transformation on the extracted information – this could include entity extraction, natural language processing, data mapping, field normalisation, etc.
- Implementing cluster management, log management and other on-going administrative functions,
- A search user interface – developing a modern responsive search user interface can take between weeks and months,
- Integrating your search application with security infrastructure such as LDAP, Active Directory (via LDAP), SAML or Kerberos,
- Implementing document level security to ensure users only have access to documents for which they have permission.
Attending to the above tasks will take an experienced team at least six man-months; a less experienced team will take longer, possibly much longer.
Fusion addresses each of the above Solr implementation challenges and Fusion Server offers many additional capabilities.


Query Workbench
Fusion's Query Workbench supports simulating and tuning the query process. Stages can be configured which enable pre- and post-processing of the query submitted to Solr. Stages available include:
| Security Trimming | Enables security trimming of the query. Documents returned will be limited based upon those accessible to the user in the underlying repository. |
| Field Facet | Add a Solr Field Facet query to the search pipeline. |
| Landing Pages | Allows a specific page, or pages to be returned in response to specific user queries. |
| JDBC Lookup | Used to enhance either the query or result environment with information from a relational database. |
| Boost with Signals | Selectively improve the relevance of the returned documents from aggregated user relevance feedback. |
| JavaScript | Incorporate custom logic into the Solr query pre- or post-processing. |
| Boost Documents | Add boosting parameters to matched documents based upon specific search terms. |
| Block Documents | Remove documents from the query based upon Block Documents rules. |
| Machine Learning | Apply a compiled Apache Sparc machine learning model to aspects of the request and store the result of the analysis in a request field or or a field in the pipleline context (for access by future pipeline stages). |
These are some of the pipeline stages which are available to augment the query processing, or results. In the figure on the right, the workbench displays the pipeline stages, a selected pipeline and the query results.
Indexing Workbench
The Fusion Indexing Workbench enables specialist processing of documents during indexing. Some of the processing stages available include:
| Apache Tika Parser | Uses Apache Tika to extract indexable text from rich file formats such as Microsoft Office and PDF. |
| Exclude Documents | Documents which match all of the configured Boolean rules are excluded from indexing. |
| Find and Replace | Remove or replace text within a field. |
| JDBC | Look up information in a database and augment the document being indexed. |
| Machine Learning | Similar to the query stage, the Machine Learning indexing stage can augment a document with the output from a trained machine learning model. Documents can be classified, or a risk profile could be attached. |
| Named Entity Recognition | Uses Apache OpenNLP (Natural Language Processing) to extract named entities (customers, organisations, legislative references, etc.) from document text. The extracted entities will be stored in a document field. Extract customer names, invoice numbers or other metadata which may be used for grouping or faceting within searches. |
| REST Query | Augment the document being indexed with the content of a call to another enterprise information system. |
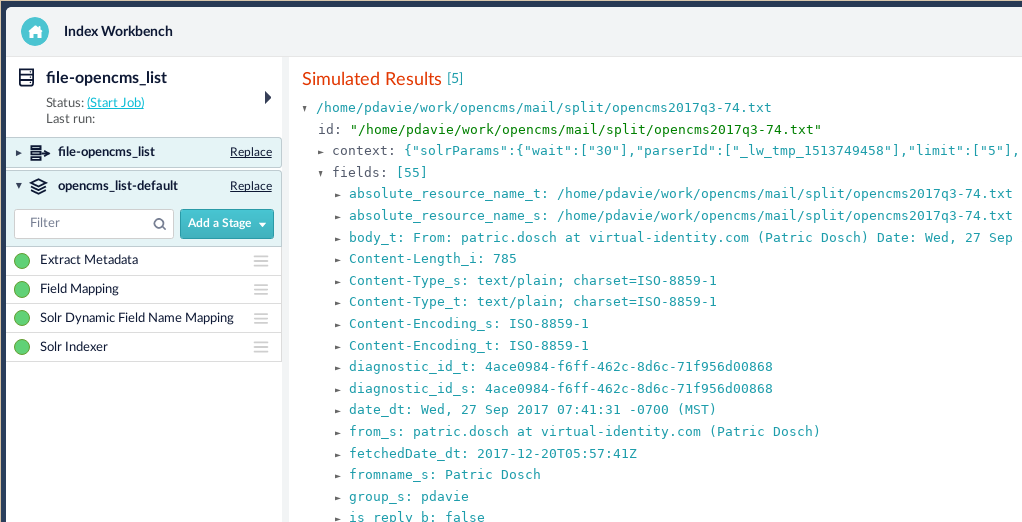
The figure on the left depicts the indexing workbench. The indexing workbench displays the parser, the indexing pipeline stages and simulated indexing results from processing sampled documents.
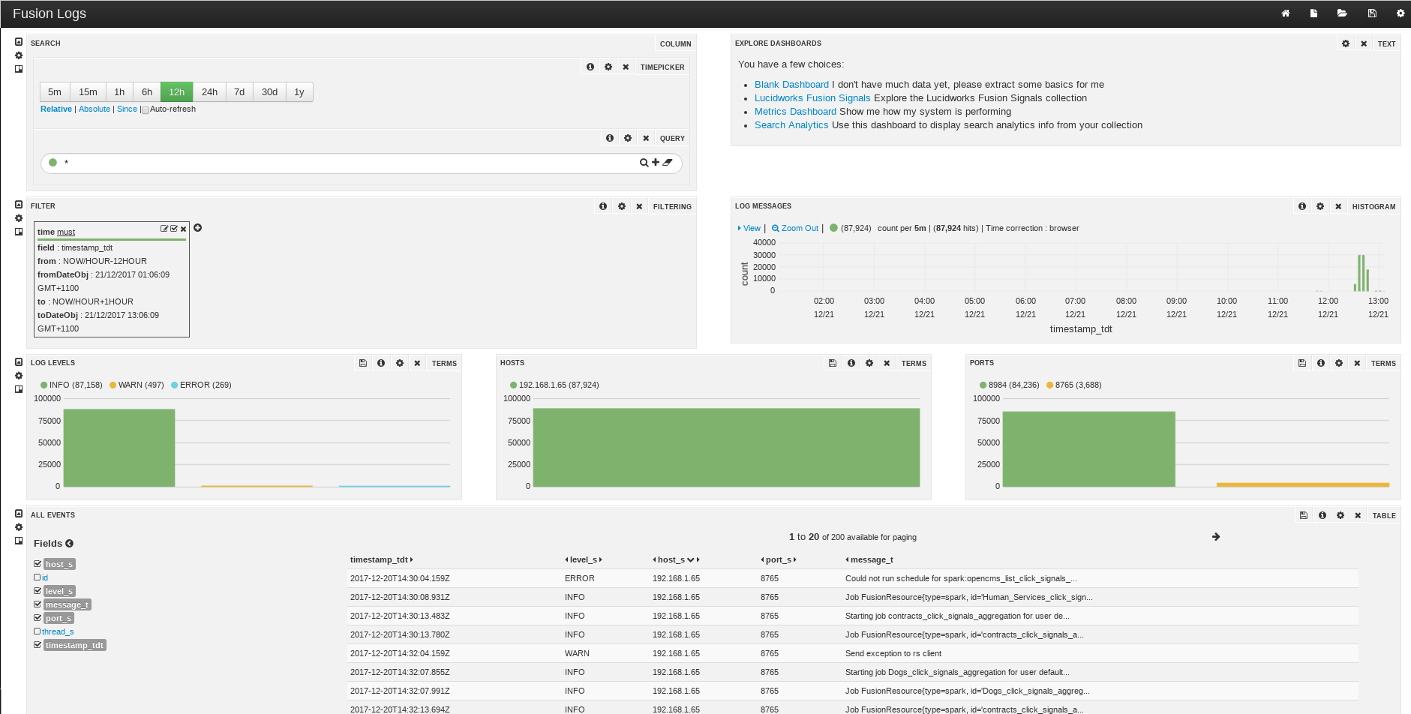
Fusion Server provides dashboards to monitor and measure processing and performance. Custom dashboards can be created to facilitate interactive analysis and reporting over Fusion logs.
In addition, Fusion Server can be queried with SQL allowing advanced analytics with products like Tableau.

Fusion Server supports querying trillions of documents from an unlimited number of data sources and data formats.
Fusion Server is built with open source, open core Apache Solr, the most popular, reliable, and powerful search technology in the world.
Apache Spark provides a processing framework that can produce aggregates and perform other complex processing and algorithms on massive volumes of raw data.
Process incoming data streams and feeds with real-time ingestion so the index is always up to date.


Fusion Server supports querying trillions of documents from an unlimited number of data sources and data formats.
Resources
The following resources provide more information about Fusion Server:
Videos
Lucidworks and Thomson Reuters for Improved Investment Performance
Lucidworks and Thomson Reuters for Improved Investment Performance
The webinar demonstrates integrating Thomson Reuters Intelligent Tagger (TRIT) with Lucidworks Fusion to create a next-generation financial research platform Finance 360. Finance360 is built using Fusion App Studio and provides a compelling demonstration of App Studio's capabilities.
Skip to the relevant part of the video for you using the following time indexes.
| Time Index | Description |
|---|---|
| 01:40 | Introduction to TRIT |
| 14:55 | Lucidworks Introduction |
| 18:00 | Fusion Introduction |
| 22:41 | TRIT financial use cases |
| 26:19 | Fusion financial use cases |
| 27:50 | Fusion Architecture |
| 31:04 | TRIT Fusion integration architecture |
| 35:00 | Finance 360 example application |
| 43:00 | Fusion Administration UI - behind the scenes magic |
County of Sacremento: Replacing GSA with Fusion
Evan Sayer, Senior Search Engineer at Lucidworks and Guy Sperry, Enterprise Content Management and Big Data Architect for the County of Sacramento talk about the journey replacing Google Search Appliance with Fusion. For the county, Fusion provided a cheaper and more flexible option. Learn how the County now relies upon Fusion as a geospatial data and NOSQL repository and also how the County implemented a secure search over two million documents in a morning!
| Time Index | Description |
|---|---|
| 05:00 | Fusion Benefits |
| 11:45 | GSA weaknesses and comparisons with Fusion |
| 15:50 | GSA scalability comparison with Fusion |
| 17:10 | Fusion benefits – control granularity |
| 22:55 | Fusion scalability |
| 24:40 | Getting started with Fusion |
| 28:47 | Introduction to the County of Sacremento |
| 33:55 | Fusion as a spatial data repository for the County |
| 35:50 | Custom log analysis (and alerting) with Fusion |
| 37:10 | Fusion as a NOSQL repository |
| 38:33 | County GSA experience |
| 42:50 | Legal search case study |
Fusion for Business Intelligence
September 14, 2016 Lucidworks Senior Systems Engineer Allan Sylek explores the difference between simple querying and data mining, using Fusion to turn raw data into insight. Allan covers a wide range of Business Intelligence applications including Enterprise Search to Log Analytics and how Fusion is applicable to all of these applications.
| Time Index | Description |
|---|---|
| 01:55 | BI mythology: Parable of the Beer and the Diapers |
| 04:20 | The Data/Information/Knowledge/Wisdom pyramid |
| 07:45 | What is Enterprise Search? |
| 10:10 | Aspects of Enterprise Search |
| 12:07 | Fusion for Enterprise Search |
| 13:35 | Fusion Index and Query pipelines |
| 16:15 | Indexing 101 |
| 18:15 | Ranking measures |
| 19:39 | Relevance measures |
| 21:36 | Statistics vs Data Mining vs Machine Learning (vs Artificial Intelligence) |
| 25:44 | What is Business Intelligence? |
| 27:10 | Why Fusion for Log Analytics? |
| 28:37 | Massive-scale log analytics |
| 29:28 | Signals & Recommendations |
| 30:20 | Visualisation & Insight with SILK |
| 32:40 | Where does Fusion Fit? |
| 35:25 | Questions & Answers |
So where to now?
Eager to know more? Perhaps a demonstration is the next step. Get in touch below.